
티스토리 뷰
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다.
Chatper 2. 기초 알고리즘
12강. 투 포인터 사용 예제 2

어제 강의를 들으면서 하나 의문이었던 건, 투 포인터 알고리즘의 개념을 설명할 때와 예제 풀이에서 포인터 설정이 달랐던 거였다. 질문 했는데 AI가 답변을 달아줬다 ㅎㅎ..
Q. 투 포인터 알고리즘 설명하실 때는 main을 0인덱스로 sub를 가장 끝 인덱스로 두고 말씀하셨는데, 예제 풀이에는 왜 main과 sub를 둘 다 0으로 두고 시작하나요?
A. 네카라쿠배 취업 끝장내는 파이썬 코딩테스트 마스터 강의를 담당하는 AI가 생성한 답변입니다.
투 포인터 알고리즘에서 main과 sub 포인터의 초기 위치는 문제의 성격에 따라 다르게 설정될 수 있습니다. 일반적으로 두 포인터를 모두 0으로 시작하는 경우는 배열의 시작부터 끝까지 순차적으로 탐색할 때 사용됩니다. 예를 들어, 부분합을 찾거나 특정 조건을 만족하는 구간을 찾을 때 유용합니다.
반면, main을 0 인덱스로, sub를 가장 끝 인덱스로 두는 경우는 배열의 양 끝에서부터 중앙으로 수렴해가며 조건을 만족하는 경우를 찾을 때 사용됩니다. 예를 들어, 정렬된 배열에서 두 수의 합이 특정 값을 만족하는 경우를 찾을 때 유용합니다.
따라서, 예제 풀이에서 두 포인터를 모두 0으로 시작한 것은 해당 문제의 요구사항에 맞게 배열의 시작부터 탐색을 진행하기 위한 설정일 것입니다. 문제의 성격에 따라 포인터의 초기 위치를 적절히 설정하는 것이 중요합니다. 수강하신 강의에서 제공하는 아래 pdf 파일들 확인해 보시는 것도 좋을 것 같습니다.
문제: 7795번: 먹을 것인가 먹힐 것인가
풀이 방법 1) 모든 경우 계산
순열 방식
시간 복잡도: O(NM) --> 비효율적
풀이 방법 2) 투 포인터 알고리즘
a > b 인 경우, main 포인터를 움직이고
a <= b 인 경우, sub 포인터를 움직인다.
이 때, 시간 복잡도는 비교 연산을 몇 번 했는가? 를 세면 된다.
> 1번 비교할 때 main 한 번 움직이고, <= 1번 비교할 떄, sub 포인터 한 번 움직인다.
즉, 1비교 = 1움직임이고, 배열의 길이가 각각 N과 M이므로
시간 복잡도는 O(N+M)이 된다.
강사님 풀이
T = int(input())
for _ in range(T):
N, M = list(map(int, input().split()))
A = list(map(int, input().split()))
B = list(map(int, input().split()))
A = sorted(A)
B = sorted(B)
main = 0
sub = 0
count = 0
while main < N:
# B의 끝에 도달했으면
if sub == M:
count += sub # 현재 A[main]보다 작은 건 M개니까 다 더함
main += 1 # 다음 A로 넘어감
else:
if A[main] > B[sub]: # A[main]이 B[sub]보다 크면
sub += 1 # 더 큰 B를 보기 위해 오른쪽으로 이동
else:
count += sub # 지금까지의 작은 B 개수를 더하고
main += 1 # 다음 A로 이동
print(count)
내 풀이
나도 알아. 분기 복잡한거. 생각한대로 쓰면 이렇게 되잖아 ㅡㅡ
그래도 답은 맞췄다고.
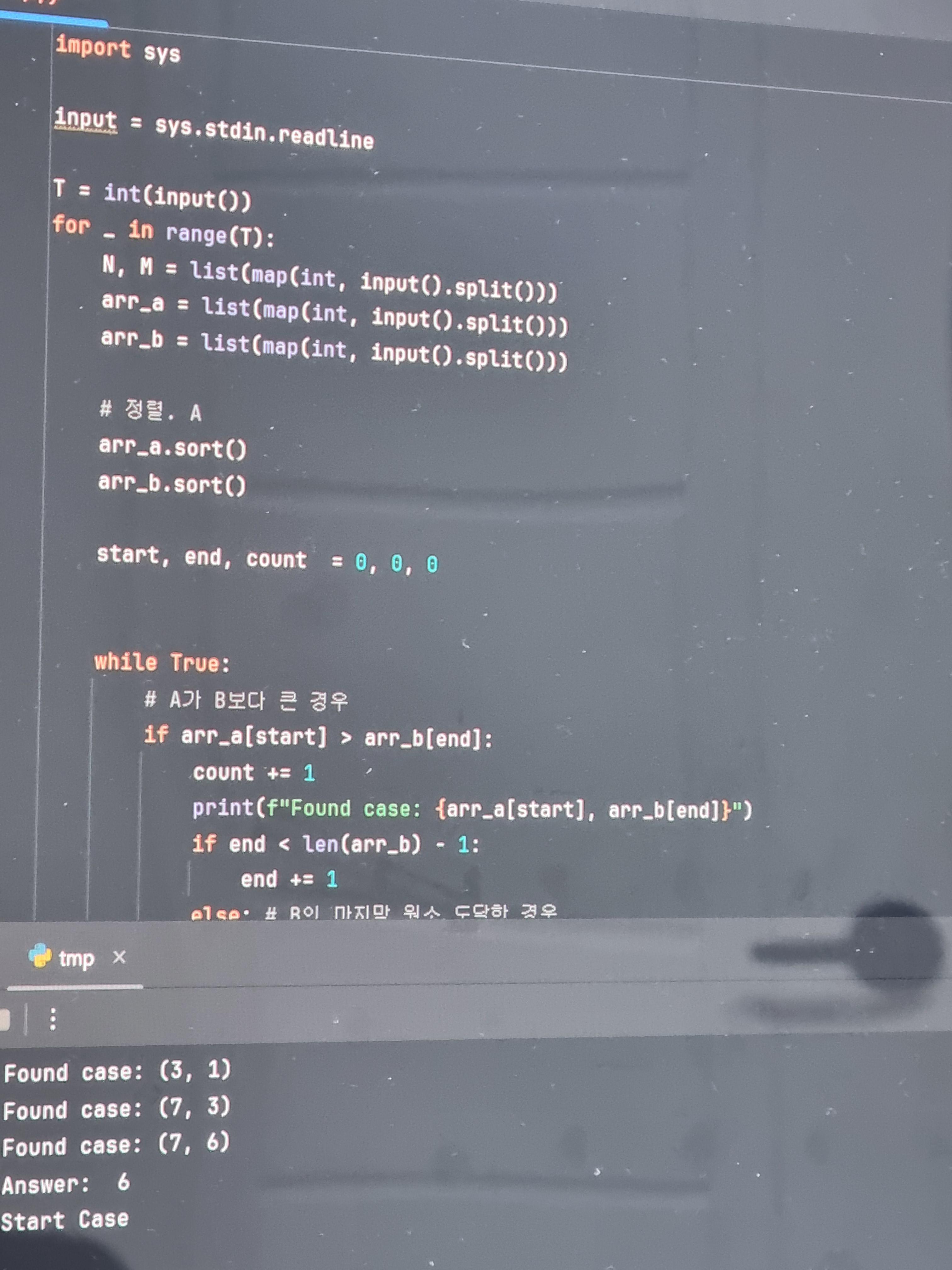
import sys
input = sys.stdin.readline
T = int(input())
for _ in range(T):
N, M = list(map(int, input().split()))
arr_a = list(map(int, input().split()))
arr_b = list(map(int, input().split()))
# 정렬. A
arr_a.sort()
arr_b.sort()
start, end, count = 0, 0, 0
while True:
# A가 B보다 큰 경우
if arr_a[start] > arr_b[end]:
count += 1
print(f"Found case: {arr_a[start], arr_b[end]}")
if end < len(arr_b) - 1:
end += 1
else: # B의 마지막 원소 도달한 경우
count += len(arr_a[start+1:]) * len(arr_b)
break
else:
if start < len(arr_a) -1:
start += 1
else:
break
print("Answer: ", count)
내 풀이와 차이점
1. 루프 방식
나:
A[main] > B[sub] 인 경우 찾고, 그럴 때마다 나타나는 조건 if 처리
강사:
- A[main] > B[sub] 인 동안 sub += 1 해주면
- 결국 sub은 현재 A[main]보다 작은 B 원소의 개수
이런 생각 우째하노ㅡㅡ 똑똑하네 🥲
끝까지 갔는지 먼저 체크하는 게 낫구나...
2. sub 인덱스 이동 가능 확인 조건문
나: if end < len(arr_b) -1
강사님: if sub == M
ㅋㅋ... ㅠㅠ
3. sub 인덱스가 마지막에 도달했을 때, 처리 방식
ex) A 배열에서 7, B 배열에서 6인 경우. A 배열의 8이 남아있고 8은 (8,1), (8,3), (8,6) 이렇게 모든 B 배열에 대해서 가능하다.
나:
len(arr_a[start+1:]) * len(arr_b)
강사:
sub 인덱스 옮기고 (=배열 이탈) 옮긴 인덱스를 정답 count에 더함. 이후에 main 포인터 이동
if sub == M:
count += sub
main += 1
인덱스는 내 앞에 원소의 갯수와 같기 때문에 !
ex) [1, 2, 3, 4, 5] 에서 마지막 5의 인덱스 4는 내 앞에 4개 원소가 있음을 의미
Abit.ly 다운받기
abit.ly
아.. 태그 넣는 게 아래 따로 있었구나...
싸늘하다...
'Python > 코딩테스트' 카테고리의 다른 글
| 패스트캠퍼스 환급챌린지 12일차 : 네카라쿠배 취업 끝장내는 파이썬 코딩테스트 마스터 (1) | 2025.04.12 |
|---|---|
| 패스트캠퍼스 환급챌린지 11일차 : 네카라쿠배 취업 끝장내는 파이썬 코딩테스트 마스터 (0) | 2025.04.11 |
| 패스트캠퍼스 환급챌린지 9일차 : 네카라쿠배 취업 끝장내는 파이썬 코딩테스트 마스터 (2) | 2025.04.09 |
| 패스트캠퍼스 환급챌린지 8일차 : 네카라쿠배 취업 끝장내는 파이썬 코딩테스트 마스터 (1) | 2025.04.08 |
| 패스트캠퍼스 환급챌린지 7일차 : 네카라쿠배 취업 끝장내는 파이썬 코딩테스트 마스터 (3) | 2025.04.07 |