
티스토리 뷰
내가 공부하려고 적는, 문자열이 있는 데이터프레임 처리하기
process (기존)
데이터 필드 타입 살펴보기
data frame : numeric(38개 열) + categorical (3개 열)
label : categorical (5개의 값)
df.shape (4898431, 42)
null 값 보기
다행히 null값 없음
train_test_split
from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(df.drop('label', 1), df['label'])convert string to int
xfrom sklearn.preprocessing import LabelEncoderfrom sklearn.preprocessing import OneHotEncoderlbe = LabelEncoder()ohe = OneHotEncoder()protocol_encoded = lbe.fit_transform(x_train['protocol_type'])protocol_encoded = protocol_encoded.reshape(len(protocol_encoded),1)onehot_encoded = ohe.fit_transform(protocol_encoded).toarray()x_train['protocol_type'] = onehot_encodedx_train, x_test, y_train, y_test 모두 LabelEncoder와 OneHotEncoder를 사용하여 numeric으로 변환 후 바로 데이터셋에 집어넣음 --> 결과적으로 제대로 안들어감;;
RandomForest 모델 적용하기
xxxxxxxxxxfrom sklearn.ensemble import RandomForestClassifierclf = RandomForestClassifier(n_estimators=10, max_depth=2, random_state=0)clf.fit(x_train, y_train)clf.predict(x_test)clf.score(x_test,y_test) # 0.986
수정 1. LabelEncoder 객체 중복 방지
xxxxxxxxxx# 기존protocol_encoded = lbe.fit_transform(x_train['protocol_type'])service_encoded = lbe.fit_transform(x_train['service'])flag_encoded = lbe.fit_transform(x_train['flag'])기존에 각 열 마다 레이블인코더를 바로 fit_transform했는데 이러면 처음에 protocol_type열에 대해 학습하고 변환한 객체를 그대로 다시 service열에 쓰게되기때문에 X.
xxxxxxxxxx# 개선lbe_prot = LabelEncoder()lbe_serv = LabelEncoder()lbe_flag = LabelEncoder()protocol_encoded = lbe_prot.fit_transform(x_train['protocol_type'])이런식으로 각 열에 맞게 객체를 만들어주어야한다!!
수정 2. OneHotEncoder로 고친 후 기존 df에 넣기
xxxxxxxxxx# 기존x_train['protocol_type'] = onehot_encoded # 개선x_train_new = pd.concat([x_train.drop('protocol_type',1 ), pd.DataFrame(onehot_encoded)], 1)기존방식으로하면 기껏 인코더 변환했는데 값이 [0,1,0] 이라면 첫 번째 값인 0만 데이터 프레임에 들어간다.. 그러니 concat으로 붙여넣어야한다.
수정3. 범주형이면 무조건 OneHotEncoding?
위의 protocol_type열은 unique()값이 3개였기에 원핫인코딩을 하는데 문제가 없었다. (데이터프레임 크기에 영향이 적음). 그러나 열의 unique()값이 70개라면? 그렇다면 70개의 열이 새로 생성되고 이는 모델의 성능에 영향을 미칠 수도 있다.

row는 약 367만개인데 서비스열의 카운트가 10미만으로 매우 작은 행들도 있다. 이런행까지 모두 열로 만들기는 부담스러우니 적당히 카운트가 적은 열들은 모아 '기타' 등으로 바꾸자. 약 0.01%, 3만6천개를 기준으로 이보다 카운트가 적으면 기타로 모두 넣는다.
xxxxxxxxxxd = x_train['service'].value_counts().to_dict()new_d = {k:v if v>(0.01*len(x_train)) else 'etc' for (k,v) in d.items()}x_train['service'].replace(new_d)
수정4. 데이터 열의 type만 보는 함정에 빠지지마라
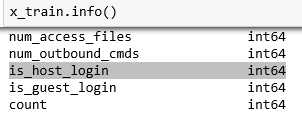
x_train열에는 obj 3개에 나머지열은 모두 int였다. 그래서 문자열만 숫자형으로 변환후 랜덤포레스트를 돌렸는데 열을 자세히 보면 is_host_login이라는 열이 있다. 그리고 이 열의 값을 살펴보면 오직 0과1 두개의 값으로만 구성되어있다. 즉, 이 열은 호스트가 로그인했는지 안했는지 나타내는 범주형 열이라는 사실 ^-^ .. 깔깔깔 범주형으로 처리해주어야겠죠?
'데이터 분석 > ML' 카테고리의 다른 글
| 범주형데이터 인코딩 OneHotEncoder, get_dummies 의 차이점 (0) | 2019.09.03 |
|---|---|
| SVM 기초 빠르게 훑어보기 (0) | 2019.06.19 |
| 정규식 (0) | 2018.11.09 |
| 알고리즘 체인과 파이프라인 (0) | 2018.11.07 |